
AI Gateways (LLM Gateways) Explained: When You Need One and How to Choose
/ Arvid Andersson
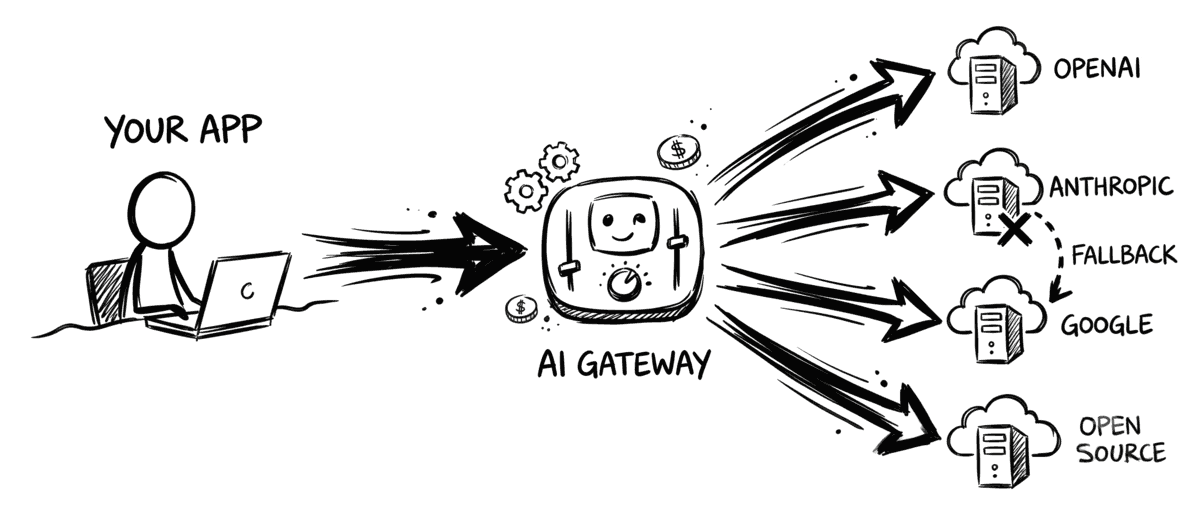
An AI gateway sits between your application and the LLM providers it calls, giving you one API in front of many models. It is one of the first abstractions worth adding once you move past a single provider, and one of the easiest to add too early. This guide covers what a gateway does, how to tell whether you need one yet, and how the main options compare as of June 2026.
Want a filterable side-by-side of the products mentioned here? See the Observability & Analytics comparison.
What a gateway actually does
One endpoint in front of many providers. The common jobs:
- Unified API. One interface, usually OpenAI-shaped, so your app does not reimplement each provider's auth, request format, and response shape.
- Routing and fallbacks. Send requests to the right provider, retry on failure, fall back to a backup model when one is rate-limited or down.
- Cost control. Track tokens and spend per key, project, or team, cap budgets, and cache repeated or semantically similar requests.
- Governance. One set of keys to manage, plus rate limits, access control, and guardrails applied in one place instead of per service.
Do you need one yet?
It depends on where you are. If you call a single provider and have no near-term plans to add another, a direct SDK call is simpler, has no extra hop, and gives you nothing to operate, so a gateway is premature at that stage. But once you are running real traffic across more than one provider, the calculus flips fast, and putting a gateway in early is far cheaper than retrofitting one after the workarounds have spread through your code.
The case for one shows up at specific moments: you add a second provider and want to switch between them without rewriting code, a provider outage takes your app down and you want automatic failover, or finance starts asking where the spend is going and you have no per-project answer. A useful tell is that if your codebase already carries fallback logic, retry logic, provider selection, and scattered API keys, you are already building a gateway, just without the shared tooling or the dashboard. At that point adopting one stops being premature.
For a one or two provider prototype, a thin router you write yourself, a small wrapper that maps providers to SDK calls with a fallback chain, is often the better trade. You own every failure mode and add no dependencies. The gateway earns its place when the number of providers, services, and people touching the system grows past what that wrapper can carry.
Why teams adopt one
Four reasons come up repeatedly, roughly in order of how often they trigger adoption.
- Swap models without rewrites. The fastest-moving advantage in this space is using a better model the week it ships. A gateway lets you change the target model in one place rather than across every service.
- Resilience. Provider rate limits, policy rejections, and outages are routine at production scale. Automatic fallback to a backup model, with retries and load balancing, keeps the app up when one provider has a bad day.
- Cost visibility and control. Token spend is easy to lose track of, and a common surprise is expensive models doing work a cheaper one could handle. Centralized tracking, budgets, and caching make spend legible and cappable.
- Key and access management. One key for your apps instead of provider secrets spread across frontend, backend, and services, with rotation and access control handled in one spot.
The options, by type
Gateways fall into three rough groups. The split that matters most in practice is whether you run it (self-hosted) or consume it (managed), because that decides how much infrastructure you take on.
Self-hosted, open-source proxies
LiteLLM is the widely used open-source option: a single OpenAI-format interface to a long list of providers, available as a Python library or a self-hosted proxy server. The proxy adds virtual keys with per-key, team, and project budgets, cost tracking, routing with retries and fallbacks, and callbacks into observability tools. It is the strongest pick when your platform team wants to own the control plane outright. The trade is exactly that ownership: you run the proxy, its database, and the on-call surface around it, which is real operational load once it is in the request path. If you self-host any gateway, pin your dependencies and prefer signed images, a gateway holds every provider key you have, so it is a high-value target worth treating carefully.
Portkey has an open-source gateway core (MIT, self-hostable) with conditional routing, fallbacks, load balancing, retries, caching including semantic caching, and built-in guardrails, plus a hosted platform that layers on observability, prompt management, and governance. Worth knowing which piece you need: the proxy is open source, but the full dashboard and enterprise control plane are part of the commercial product.
CC Switch is a lighter-weight option in the same self-hosted lane, aimed at switching between providers through a single interface. It fits smaller setups that want provider flexibility without standing up a full platform.
Managed, platform gateways
Cloudflare AI Gateway runs at Cloudflare's edge and adds with one line of code: request retry and model fallback, caching, rate limiting, usage and cost metrics, logging, and guardrails. Core features are free on all plans, with metered add-ons. Its dynamic routing is rules and budget based (for example, fall back to a cheaper model once a dollar budget is hit) rather than content-aware. It is not self-hostable.
Vercel AI Gateway is a hosted unified endpoint to hundreds of models with automatic retry and fallback, load balancing, spend monitoring, and a bring-your-own-key option. Notably it passes through provider pricing with no markup on tokens, including on BYOK, charging instead through optional add-on features. Like Cloudflare, it is managed only.
TrueFoundry is a managed gateway with the broadest deployment range of this group: fully managed SaaS, hybrid, self-hosted on-prem or cloud, VPC, and air-gapped. It covers latency-based load balancing with fallbacks, caching, per-user and per-service rate limits and quotas, token-level cost tracking, input and output guardrails, and RBAC with OAuth 2.0. Its distinguishing feature is that deployment flexibility plus enterprise governance, which fits teams with data-residency or air-gapped requirements. Pricing runs from a free developer tier up through usage-based paid tiers to custom enterprise.
Aggregator APIs that double as gateways
OpenRouter is a well-known example: a hosted API fronting a large catalog of models from many providers behind one key and one bill, with automatic provider fallback and routing variants for lowest cost or highest throughput. It passes through provider pricing with no markup on inference, charging a small fee on credit purchases instead (and a small percentage on BYOK above a monthly free allowance). It is the fastest way to get breadth plus routing without running anything, the trade being that you are consuming a hosted service rather than owning the layer. Several smaller, often region-focused aggregators take the same shape, including EUrouter, Cortecs AI, and FerryAPI.
Requesty sits in the same managed lane but leans further toward the governance end: one OpenAI-compatible API across 400+ models from 20+ providers, with routing, automatic fallbacks, and caching, plus per-key spend limits, team budgets, and spend alerts. Its paid tier is a flat 5% markup on base model costs with bring-your-own-key, and the enterprise tier adds RBAC, audit logs, SSO, and SOC 2, with EU data residency available on a separate endpoint. It is managed only, which is the trade for not running anything.
Comparison
| Product | Type | Deployment | Open source |
|---|---|---|---|
 LiteLLM LiteLLM |
Self-hosted proxy / library | Self-host or managed | Yes (core) |
 Portkey Portkey |
Proxy + platform | Self-host or managed | Gateway core (MIT) |
| Self-hosted proxy | Self-host | Yes | |
| Cloudflare AI Gateway | Managed platform | Managed (edge) | No |
 Vercel AI Gateway Vercel AI Gateway |
Managed platform | Managed | No |
| Managed platform | SaaS, hybrid, self-host, VPC, air-gapped | No | |
| Aggregator API | Managed | No | |
| Aggregator API + governance | Managed | No |
Features and deployment options as of June 2026. Model and provider counts cited by vendors are not independently verified.
How to choose
Once you have decided you need a gateway, the questions that separate a good demo from a tool that survives production are rarely about price per million tokens. The ones worth asking up front:
- Cost attribution. Can you break spend down by project, service, and key without building a second reporting layer?
- Audit trails and compliance. Once more than one team shares the gateway, its logs become part of your governance story. Can you see who used which model, where data went, and why a fallback fired, and export that for a SOC 2 or similar review? Gateways differ a lot here: TrueFoundry and Requesty list RBAC and audit logging on their enterprise tiers, while lighter options focus on routing and leave the audit layer to you.
- Provider visibility. Can you see which upstream provider actually served a given request, not just a model name?
- Partial failures. What happens during latency spikes, flaky responses, and quota weirdness, not just full outages?
- Protocol coexistence. Can OpenAI-style and Anthropic-style tooling run side by side without a pile of glue code?
- Infrastructure ownership. How much are you signing up to run yourself, and do you have the team for it?
- Model freshness. How quickly do newly released models show up?
Mapped to the options: if you want maximum control and have the platform muscle, a self-hosted proxy like LiteLLM or Portkey's core fits. If you want the layer handled for you, Cloudflare and Vercel are low-effort managed routes, and TrueFoundry adds enterprise governance and flexible deployment for teams with residency or air-gapped needs. If you mostly want breadth and routing without running anything, an aggregator like OpenRouter gets you there fastest. As a rough rule of thumb, the trade tips toward a gateway once you pass a couple of developers or a few thousand requests a day. Below that, direct calls usually win.
Where it is heading
The gateway started as a convenience layer, one API instead of five. It is turning into a permanent part of the stack, and three signals point that way.
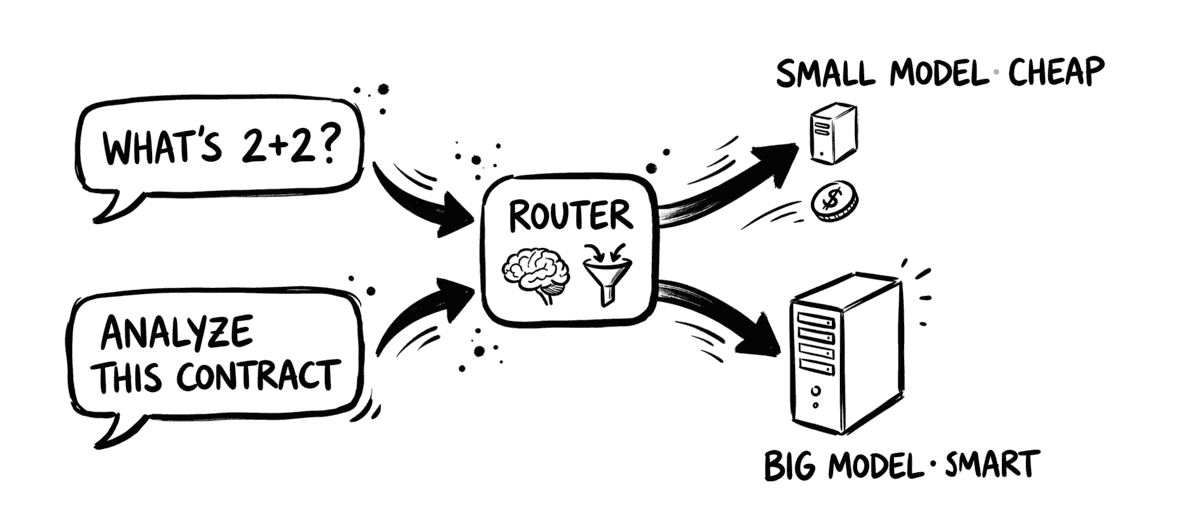
First, the routing is getting smarter. Semantic routing picks a model by the complexity of each request, a cheap small model for simple work and a stronger one for hard work, rather than by fixed rules. It shows up in dedicated open-source projects like the vLLM Semantic Router and as a feature in commercial gateways, and it is distinct from the budget-based dynamic routing most gateways already do. As model choice multiplies and prices keep moving, the decision of which model handles which request stops being something you hardcode and becomes something the gateway does for you. That kind of automatic cost-versus-quality tuning is hard to get by calling providers directly.
Second, the scope is widening. As agents and tool use spread, gateways are reframing from LLM proxy toward a control plane that also governs agent, tool, and MCP traffic. The same things a gateway already does for model calls, routing, rate limits, cost tracking, access control, are exactly what an agent making dozens of tool calls per task needs, so the gateway is becoming the natural place to enforce them once rather than per service.
Third, the market is treating it as critical infrastructure. The category is consolidating and attracting serious money: Palo Alto Networks acquired Portkey (announced April 2026, completed May 2026) to fold the gateway into its security platform, and OpenRouter raised a large round (led by Alphabet's CapitalG) in May 2026. A security vendor wiring a gateway into its platform, and aggregators raising at scale, are both bets that this layer stays.
All three signals point the same way. The gateway is becoming the place where model access, cost, and policy are decided, which is a good reason to treat it as a deliberate architectural choice rather than a stopgap you bolt on once something breaks.
Related reading
A gateway is one layer of the stack. These cover the ones it sits next to.
Frequently asked questions
What is an AI gateway?
An AI gateway (or LLM gateway) is a proxy that sits between your application and one or more LLM providers. It exposes a single API, usually shaped like the OpenAI chat-completions endpoint, and handles the cross-cutting work that would otherwise be scattered through your code: routing requests to the right provider, retries and fallbacks, caching, rate limits, cost tracking, and access control. Your app talks to one endpoint with one key, and the gateway deals with each provider's specifics behind it.
Do I actually need an AI gateway?
If you call a single provider and have no plans to add another, a direct SDK call is simpler and a gateway is overhead. The case for one appears when you add a second provider, need failover when a provider has an outage, or need cost visibility across providers and teams. A useful tell: if your code already carries fallback logic, retry logic, provider selection, and key management, you are already building a gateway, just without the shared tooling. For a one or two provider prototype, a thin router you write and control is often the better call.
What is the difference between an aggregator like OpenRouter and a gateway like LiteLLM or Portkey?
An aggregator is a hosted API that fronts many models behind one key and one bill, so you call its endpoint and it handles provider access for you. A gateway is the control layer you put in front of provider calls, whether those go direct or through an aggregator, to add routing, fallbacks, cost attribution, and governance. The lines blur, OpenRouter does routing and fallback, and several gateways can call an aggregator as one of their providers, but the practical difference is ownership: an aggregator is a service you consume, a self-hosted gateway is infrastructure you run.
Are there open-source, self-hostable AI gateways?
Yes. LiteLLM is open source and runs as a self-hosted proxy or library. Portkey's gateway core is open source (MIT) and self-hostable, though its full observability and governance dashboard is part of the hosted product. Managed-only options like Cloudflare AI Gateway and Vercel AI Gateway are not self-hostable. Self-hosting trades a managed service for control over data and routing, at the cost of running a high-throughput component yourself.
What are alternatives to Cloudflare AI Gateway?
Cloudflare AI Gateway is a managed, edge-hosted gateway with caching, rate limiting, retries, fallbacks, and usage analytics on a free tier. The main thing it does not offer is self-hosting, so if you want to run the gateway in your own infrastructure, the open-source options are LiteLLM and Portkey's gateway core. For another fully managed option, Vercel AI Gateway is comparable and passes through provider pricing with no token markup. TrueFoundry covers managed plus self-hosted, VPC, and air-gapped deployment for teams with data-residency needs. If you mainly want one API across many models without running anything, an aggregator like OpenRouter fills that role.
Which AI gateway is best for per-team cost tracking and audit logging?
Once several teams share a gateway, two needs dominate: attributing spend per team, project, and key, and keeping audit trails (who used which model, where data went, why a fallback fired) that hold up in a SOC 2 or similar review. Most gateways do the cost-attribution half; fewer do audit-grade logging out of the box. Among the managed options, TrueFoundry and Requesty list per-team budgets or quotas plus RBAC and audit logs on their enterprise tiers, and TrueFoundry adds flexible deployment (VPC, air-gapped) for data-residency needs. Self-hosted LiteLLM gives per-key and per-team budgets and lets you keep all logs in your own infrastructure, at the cost of running and securing the proxy yourself. The thing to verify is the export: can the gateway produce a log that maps to your controls, not just a usage dashboard.
What is semantic or smart routing?
Semantic routing picks a model based on the content and complexity of each request, sending simple queries to a small, cheap model and hard ones to a stronger, more expensive model. It is distinct from rules-based dynamic routing (for example, fall back to a cheaper model once a dollar budget is hit), which does not look at the request itself. Approaches range from a tiny local classifier scoring complexity to dedicated projects like the open-source vLLM Semantic Router. It is an emerging capability in 2026 rather than a settled default.
Does an AI gateway add latency?
Yes, a gateway is an extra network hop, so it adds some latency. In practice teams running gateways report the overhead as small relative to model response time, but it is real, and a self-hosted gateway under heavy traffic needs to be sized and monitored like any other proxy. The trade is latency against reliability and cost visibility: for a single-provider prototype that trade rarely pays off, for multi-provider production it usually does.
Browse all Observability & Analytics tools on Infrabase.ai
Is your product missing?