Requesty
LLM gateway and router with one OpenAI-compatible API across 400+ models
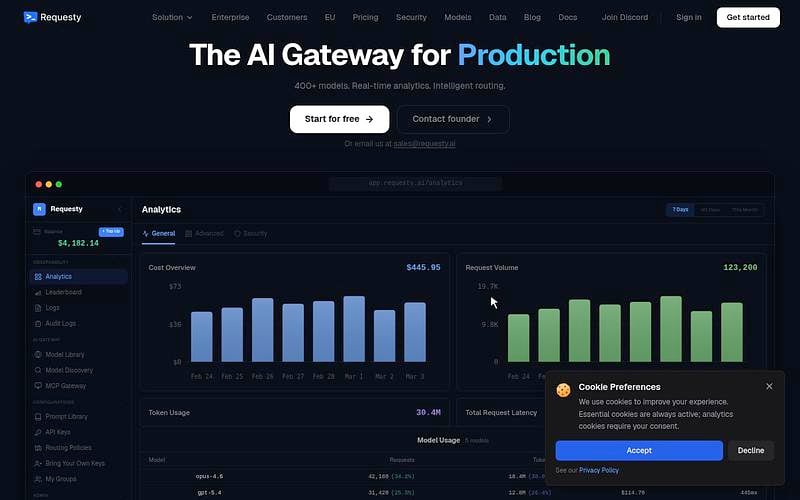
Requesty is an LLM gateway that routes requests to 400+ models across 30+ providers through a single OpenAI-compatible endpoint. It handles intelligent routing (by cost, latency, or availability), automatic failover, and prompt caching to cut token spend.
It adds per-user and per-team cost tracking, spend limits, and observability dashboards for cost, latency, error rates, and cache hits. Enterprise plans include SSO, RBAC, audit logs, guardrails, and PII detection. SOC 2, GDPR, and HIPAA compliant, with EU data residency available via a separate EU endpoint.
The free tier covers free models and 200 requests/day; paid usage is a 5% markup on base model costs with bring-your-own-keys.
Pricing: Usage-based
Requesty Alternatives
Explore 82 products in the Inference APIs category. View all Requesty alternatives.
Scaleway
European serverless AI inference APIs, 100% hosted in Europe

Infercom
European sovereign AI inference with OpenAI-compatible APIs hosted in EU datacenters
Nebius
Full-stack AI cloud with GPU infrastructure for training and inference
Work on Requesty? Feature it at the top of Inference APIs.
Is your product missing?